
The HARMONY data lake would be useless without the data processing and analysis services that are associated with it. It is the combination of the data lake with custom-made and innovative data services that allow researchers to mine the data and answer pressing research questions about blood cancers. To ensure the quality and safety of the data, a new data set must proceed through a multistep journey.
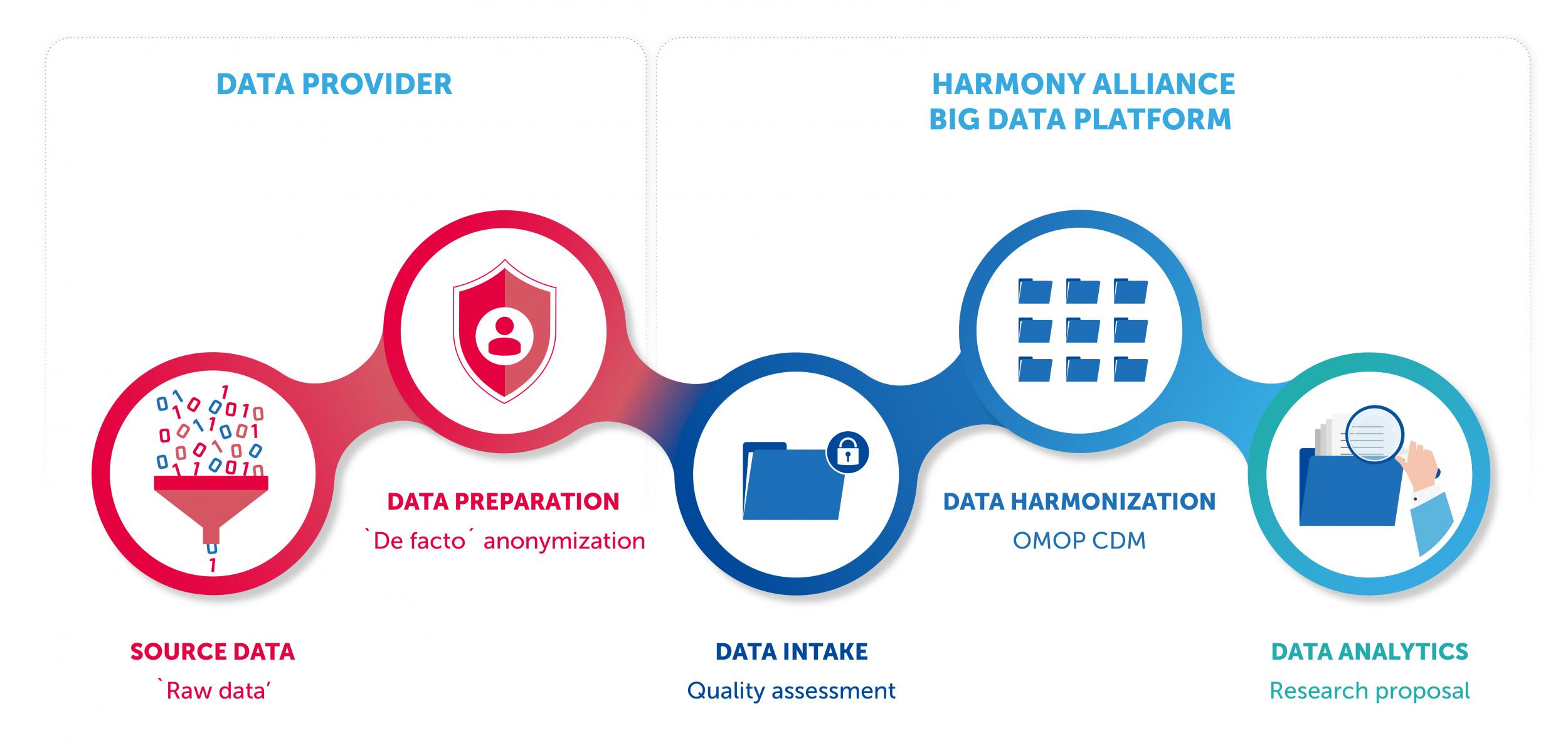
The HARMONY Alliance data processing pipeline consists of multiple steps. First, raw data is prepared and ‘de facto anonymized’ at the source. Next, it is transferred to the HARMONY Big Data Platform through a trusted third party. Then, the HARMONY data scientists perform the data intake (including quality assessment) and the data transformation to the so-called ‘OMOP common data model’. At the end of the data journey, the data is ready to be analyzed. Researchers that want to analyze the data are invited to join HARMONY and contribute new data to the platform. Ultimately, they can submit a research proposal which will be evaluated by HARMONY scientific experts. Project manager Antonio Pérez Bautista of HARMONY Partner GMV: “Data contributors sometimes expect that they can simply send us their data and immediately proceed to analyzing it. They are surprised when they discover that the process may take two months or so. The HARMONY data processing pipeline consists of several steps. After the data owner has properly prepared the data, it is anonymized and uploaded to a broker. Next, the quality of the data is evaluated, and it is harmonized with the other data in the Big Data Platform.”
Once the data is collected at the source, the first step is to prepare it to be shared with the HARMONY Big Data Platform. In the data preparation step, the data provider establishes ‘de facto anonymization’ of the raw data. HARMONY offers trainings to help data providers with this step. “HARMONY has developed a protocol to ensure that identification of the persons behind the data would require an unreasonable amount of time, cost, and manpower. This method is called ‘de facto anonymization’ It ensures a balance between anonymizing the data and keeping the value of the data,” says data manager Laura Tur Giménez of GMV. In addition to de facto anonymization, other measures have been taken to ensure the safety of the data on HARMONY’s Platform. These include technical barriers such as strict access procedures, as well as organizational measures such as trainings for users. Read more about data anonymization in HARMONY >
After de facto anonymization, the data is ready to be shared with a so-called ‘Trusted Third Party’ (TTP). This is a company called ‘Ulm’ that acts like a broker. The TTP checks if the data is properly anonymized, changes the identifier of the patient and transfers the data to the data processor. The TTP ensures that essential information about the data is preserved. This is like a fingerprint of the data, including for instance the date of collection, information about the data owner, and so on. All processes thereafter take place within the platform.
Laura Tur Giménez: “The next step is the data intake. Our initial review of the data focuses on two aspects. First, we ask data providers to submit a data dictionary in which we can find the names of the variables, a description of each variable, the possible values and the meaning of each value. Second, we profile the data, meaning that we scan all variables and their possible values. We check if there are variables or possible values that are not mentioned in the data dictionary and we detect outliers for numerical variables.”
As soon as this first review of the data is complete, the team continues with another quality assessment step. Cases will only be included in the HARMONY Big Data Platform if they are reasonably complete. HARMONY’s clinical experts have developed a list with the information that they need at the very least – the so-called ‘minimum essential data fields’. Based on this list, cases are classified as complete or incomplete. Cases that do not meet the criteria are filtered out and will not be included in the platform. For instance, the minimum required fields for AML are gender, age at disease onset, diagnosis date, overall survival, and status at last follow-up.
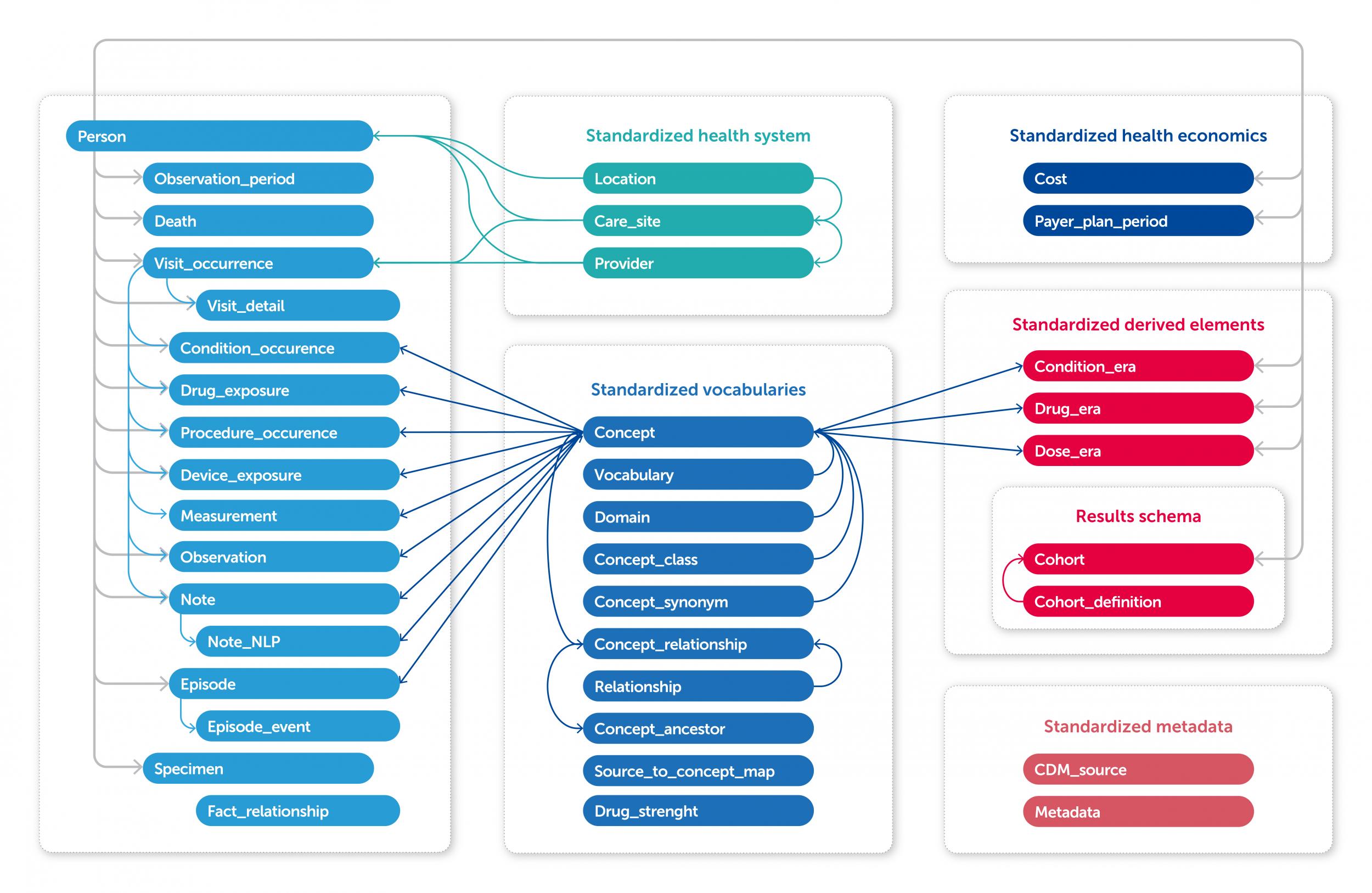
The next step is crucial: harmonizing the data with the other data sets on the platform. In the data harmonization step, HARMONY’s data scientists transform the data to a common data model called ‘OMOP’, meaning that they receive the same structure and use the same vocabulary. This enables HARMONY to combine data produced at various places in Europe, for different purposes, and using different standards. Read more about data harmonization in HARMONY >
The OMOP Common Data Model captures information through concepts. Each concept is represented by a numerical code. The code 3010813 refers to the measurement of white blood cell count. This concept belongs to the vocabulary called ‘LOINC’, which is the vocabularies available in OMOP. If a specific variable is not represented in the vocabularies available in OMOP, new vocabularies and concepts can be created as non-standard concepts.
After the harmonization step, the data reaches the last phase of its journey: the data analytics phase. This is when the scientists and analysts are working with the data. Data analysis takes place inside the platform, where a series of data analytics tools is available. “We can create a workspace and user accounts for scientists based on the research proposal that they have submitted to the HARMONY Alliance. The researchers will only obtain access to a subset of the data lake. We only extract the variables required to answer their specific research question and the cases that meet the inclusion criteria specified in their research proposal. This helps us guarantee data safety as well as efficiency,” says Antonio Pérez Bautista.
The result of all these steps are the scientific publications, which provide concrete evidence that HARMONY’s efforts are advancing science. However, in the end, what we are doing here is learning from patients’ experiences in order to reduce mortality in the future. When the scientific community reads the papers, they will focus on the scientific results, but is important to keep in mind what it takes to reach these conclusions. "The importance of the data collection by healthcare professionals; the process of quality control, harmonization, and analysis of the data; and drawing the right conclusions from the results cannot be overemphasized. In addition, the existence of the HARMONY Big Data Platform and the HARMONY Alliance itself are crucial to reach our objective to improve the lives of patients with blood cancer,” concludes Laura Tur Giménez.

Interested to read more about our data science expertise? Click here to visit #bigdataforbloodcancer blog 01/2023 >
The HARMONY Alliance is a European Public–Private Partnership for Big Data in Hematology that is capturing and mining Big Data on various Hematologic Malignancies. Funded by IMI (now IHI, Innovative Health Initiative), and uniting more than 120 organizations such as European medical associations, hospitals, research institutes, patient organizations, pharmaceutical companies, IT companies, and health technology assessment/regulatory agencies.
The inclusion of all these stakeholders reflects the HARMONY ambition to develop tools that clinicians and patients can adopt, and also be of interest to regulators, payers, and health technology assessment bodies.
This article is updated per September 2023.
Receive the latest news. Click here to subscribe!

Public-private partnership for Big Data in Hematology
HARMONY and HARMONY PLUS are funded through the Innovative Medicines Initiative (IMI), Europe's largest public-private initiative aiming to speed up the development of better and safer medicines for patients. Funding is received from the IMI 2 Joint Undertaking and is listed under grant agreement for HARMONY No. 116026 and grant agreement for HARMONY PLUS No. 945406. This Joint Undertaking receives support from the European Union’s Horizon 2020 Research and Innovation Programme and the European Federation of Pharmaceutical Industries and Associations (EFPIA).
HARMONY Coordination Office
Institute of Biomedical Research of
Salamanca (IBSAL)
Salamanca, Spain
HARMONY Communications
European Hematology Association (EHA)
The Hague, The Netherlands